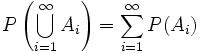Formułowanie hipotezy statystycznej rozpoczyna się zebranianiem informacji na temat populacji i jej możliwego rozkładu. Dzięki temu możliwe jest zbudowanie zbioru hipotez dopuszczalnych Ω, czyli zbioru rozkładów, które mogą charakteryzować badaną populację. Hipoteza statystyczna to każdy podzbiór zbioru hipotez dopuszczalnych.
Podział hipotez statystycznych
Hipotezy statystyczne można podzielić na:
- parametryczne - hipoteza dotyczy wartości parametru rozkładu
- nieparametryczne - hipoteza dotyczy postaci funkcyjnej rozkładu
- proste - hipoteza jednoznacznie określa rozkład danej populacji, czyli odpowiadający jej podzbiór zbioru Ω zawiera jeden element (rozkład)
- złożone - hipoteza określa całą grupę rozkładów, zaś odpowiadający jej podzbiór
- zbioru Ω zawiera więcej niż jeden element
- alternatywna - przyjmujemy ją kiedy odrzucamy hipotezę zerową

Definiujemy unormowaną zmienną Y:
Z własności bezwzględnej wartości:
Ponieważ funkcja gęstości jest dla rozkładu N(0,1) parzysta to zachodzi równość:
Wiadomo, że P(A) to to samo co 1-P(A') więc:
1 − P(Y < t) = 0,01
P(Y < t) = 0,99
A P(Y
Teraz w tablicy rozkładu normalnego znajdujemy najmniejszą wartość t dla której F(t) wynosi conajmniej 0,99. Jest to wartość 2,33.
Hipotezę H0 należy wiec odrzucić na poziomie istotności α jeżeli
Zgodnie z naszymi danymi wychodzi:
| Mn − 54 | = | 51,21 − 54 | = 2,79
Więc:
Zatem hipotezę możemy odrzucić (jeśli wyjdzie odwrotnie to piszemy że nie odrzucamy ani nie potwierdzamy - tak właśnie trzeba było zrobić na egzaminie, bo wychodziło <).
Testem statystycznym nazywamy każdą jednoznacznie zdefiniowaną regułę postępowania określającą warunki przy których należy weryfikowaną hipotezę przyjąć bądź odrzucić. Weryfikacja hipotez statystycznych odbywa się na podstawie wyników zaobserwowanych w próbie. W rezultacie test statystyczny podaje reguły, przy jakiego rodzaju wynikach próby sprawdzaną hipotezę się przyjmuje, a przy jakich odrzuca.
Weryfikowaną hipotezę nazywa się zwykle hipotezą zerową: H0
D e cy z j a
Hipoteza H0 Przyjąć H0 Odrzucić H0
Jest prawdziwa Decyzja poprawna Błąd I rodzaju. Prawdopodobieństwo popełnienia tego błędu.
Jest fałszywa Błąd II rodzaju Decyzja poprawna
Wartość prawdopodobieństwa popełnienia błędu I rodzaju - nazywamy poziomem istotności testu; najczęściej przyjmuje się = 0,05 , lub = 0,1.
Oprócz hipotezy zerowej formułujemy również hipotezę H1 ( hipotezę alternatywna), którą skłonni jesteśmy przyjąć, jeśli weryfikowaną hipotezę H0 należy odrzucić. Sprawdzian hipotezy jest to pewna funkcja wyników z próby, na podstawie której decydujemy, czy można hipotezę H0 przyjąć, czy odrzucić. Przez obszar krytyczny rozumie się taki zbiór wartości sprawdzianu hipotezy, że jeżeli zaobserwowana wartość sprawdzianu znajdzie się w tym obszarze, to odrzuca się hipotezę H0 na korzyść H1. Prawdopodobieństwo tego, że sprawdzian przyjmie wartość należącą do obszaru krytycznego, jest przy założeniu prawdziwości hipotezy H0 równe założonemu poziomowi istotności .
1. 1. Testy istotności dla wartości oczekiwanej (średniej)
Model 1. Załóżmy, że populacja generalna ma rozkład normalny N(m,) o nieznanej wartości średniej m oraz znanym odchyleniu standardowym . Z populacji tej wylosowano n elementową próbę w celu zweryfikowania hipotezy
H0: m = m0
wobec hipotezy alternatywnej H1: m m0 ,
gdzie m0 jest pewną hipotetyczna wartością średniej w populacji.
Sprawdzianem hipotezy jest statystyka:
która przy założeniu prawdziwości hipotezy H0 ma rozkład normalny N(0, 1). Jeśli H0 jest prawdziwa, to wartość bezwzględna U nie powinna przekraczać wartości krytycznej u , odczytanej z tablic rozkładu normalnego przy ustalonym poziomie istotności . Jeżeli odchylenie standardowe w populacji generalnej nie jest znane, to we wzorze (1) można je zastąpić odchyleniem standardowym s obliczonym z próby. jest to uzasadnione tylko wtedy, gdy próba jest duża: n > 30.
Model 2. Dla małych prób losowych (n 30) do sprawdzania hipotezy
H0: m = m0 wykorzystujemy statystykę:
Statystyka przy założeniu prawdziwości hipotezy H0 ma rozkład t Studenta o n-1 stopniach swobody.
1.2. Test istotności dla wariancji
Załóżmy, że populacja generalna ma rozkład normalny N(m,) o nieznanych parametrach wartości średniej m i odchyleniu standardowym . Z populacji tej wylosowano n elementową próbę w celu zweryfikowania hipotezy wobec hipotezy alternatywnej , gdzie jest pewną hipotetyczną wartością wariancji w populacji.
Sprawdzianem hipotezy jest statystyka:
Statystyka ta ma przy założeniu prawdziwości H0 – rozkład 2 o n-1 stopniach swobody.
2.3. Test istotności dla wskaźnika struktury
Na podstawie n-elementowej próby (n>100) weryfikujemy hipotezę :
H0: p = p0
wobec hipotezy alternatywnej:
H1: p p0 ,
Sprawdzianem hipotezy jest statystyka:
która przy założeniu prawdziwości hipotezy H0 ma rozkład normalny N(0, 1), przy czym X oznacza ilość jednostek o wyróżnionej wartości cechy w n-elementowej próbie.