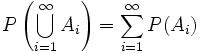Najczęściej przekształcenie liniowe wyraża się jako macierz, która działa na wektory; wówczas stosuje się nazwy wektor własny macierzy, wartość własna macierzy. W innych teoriach przekształcenia i elementy przestrzeni liniowej mogą mieć inne nazwy. Mówi się wtedy przykładowo o stanach własnych operatora, funkcjach własnych funkcjonału itp.
Niech x będzie przestrzenią liniową nad ciałem K zaś T oznacza pewien jej endomorfizm, tzn. przekształcenie liniowe tej przestrzeni w siebie. Jeśli dla pewnego niezerowego wektora przestrzeni spełniony jest warunek
gdzie
Danej wartości własnej
Często zakłada się, że K jest ciałem liczb rzeczywistych bądź zespolona, zaś na X określona jest topologia liniowa. W zastosowaniach (np. równania różniczkowe) bada się często wartości własne operatorów liniowych określonych na przestrzeniach Banacha, Hilberta itp. W dalszej części artykułu będziemy zakładać ogólnie, że X jest pewną przestrzenią Banacha, a
- Jeżeli T jest samosprzężonym operatorem liniowym na przestrzeni Hilberta X to wartości własne tego operatora są rzeczywiste, ponadto wektory własne, odpowiadające różnym wartościom własnym są ortogonalne.
- Jeżeli
 jest wartością własną operatora T to
jest wartością własną operatora T to  (założenie zupełności przestrzeni jest tu nieistotne).
(założenie zupełności przestrzeni jest tu nieistotne). - Liczba
jest wartością własną operatora T wtedy i tylko wtedy, gdy operator
 nie jest różnowartościowy.
nie jest różnowartościowy. - Wektory własne odpowiadające różnym wartościom własnym są liniowo niezależne.
- Jeśli macierz A potraktować jako macierz przekształcenia liniowego pewnej przestrzeni liniowej V to wektory własne odpowiadające tej samej wartości własnej tworzą podprzestrzeń.
- Jeśli suma wymiarów podprzestrzeni z powyższej własności jest równa wymiarowi V to wektory własne odpowiadające różnym wartościom własnym tworzą bazę tej przestrzeni
Przestrzenie skończeniewymiarowe
Przekształcenie liniowe A skończeniewymiarowych przestrzeni liniowych z ustalonymi bazami można przedstawić za pomocą macierzy A nazywanej macierzą przekształcenia liniowego.
Endomorfizmowi A na skończeniewymiarowej przestrzeni X odpowiada macierz kwadratowa A, a jej wartości własne są pierwiastkami jej wielomianu charakterystycznego
Mając do dyspozycji wartości własne
Równanie całkowe jednorodne Fredholma
Niech
Można wykazać, że odwzorowanie